Why Operator
Overview
Kubernetes 管理“有状态应用” 比较复杂,Operator提供了一种相对更加灵活和编程友好的管理“有状态应用”的解决方案。
目前大部分的分布式应用比如etcd,Redis,Kafka,Spark,TensorFlow等都有官方维护着的Operator,Operator成了开发和部署分布式应用的一项事实标准,成为容器化时代应用开发和发布的一个全新途径。
可以在Operator官方库里,找到一直维护着的一个知名分布式项目的Operator总汇:https://github.com/operator-framework/awesome-operators
虽然Operator是把一个复杂集群应用,抽象成一个具有一定“自治能力”的整体,但是这个自治能力本身不足以解决问题的时候,还需要其他手段来弥补。比如Etcd集群的备份和恢复能力,Etcd Operator就无法解决,通过Etcd Backup/Restore Operator来解决。
Background
Kubernetes 项目最具有价值的理念,就是围绕Etcd构建出的一套“面向终态”编排体系,即 “声明式API” 。
“声明式API” 核心原理,就是当用户提交一个API对象描述后,。Kubernetes通过启动“Controller Pattern”的无限循环,通过调谐来保证整个集群里各项资源的状态和你的API对象描述的需求相一致。
Operator也是相同的思想,用户提交的API对象不再是一个单位应用描述,而是一个分布式应用的集群的描述,Operator这个controller会保证集群的状态和用户提交的描述的一致。
History
《亲历者说:Kubernetes API 与 Operator,不为人知的开发者战争》 这篇文章是Operator的发起者CoreOS的邓洪超,和阿里的张磊写的,讲述了Operator的起源和背后的故事。
TPR(Third Party Resource) --> UAS(User Aggregated APIServer) --> APIServer Aggregator --> CDR(Custom Resource Definition)
Operator vs. StatefulSet
StatefulSet 是Kubernetes专门来管理有状态应用的,其核心原理就是对分布式应用的两种状态进行保持:
- 拓扑状态,节点之间的启动顺序;
- 存储状态,每个节点依赖的持久化数据。
StatefulSet 通过为节点分配有序的DNS名字来保持拓扑状态(为Pod编号),通过远程持久化数据卷方案(Pod和PV绑定)来保持存储状态,比较适用于应用本身节点管理能力不完善的项目,比如 MySQL。像Etcd这种自管理的分布式应用,有自己的数据备份和恢复方法,使用StatefulSet就很别扭,有各种限制。
完全可用在Operator里面创建和控制StatefulSet而不是Pod,Prometheus就是这么干的。
Operator vs. Helm
相比于 Helm、Docker Compose 等描述应用静态关系的编排工具,Operator 定义的乃是应用运行起来后整个集群的动态逻辑。 Helm只是部署工具,集群逻辑还是需要K8s自己来维护。
通过用Helm来部署Operator,以及新对象。
Etcd Operator
Deploy an etcd cluster with 3 nodes
# clone etcd-operator repo
$ git clone https://github.com/coreos/etcd-operator
# create clusterrole and clusterrolebinding
$ example/rbac/create_role.sh
# deploy etcd operator
$ kubectl create -f example/deployment.yaml
# deploy etcd cluster
$ kubectl apply -f example/example-etcd-cluster.yaml
Create ClusterRole and ClusterRoleBinding
- 对
Pod,Service,PVC,Deployment等API有所有权限; - 对
CRD对象有所有权限; - 对属于
etcd.database.coreos.com这个API Group的CR对象etcdbackups,etcdclusters,etcdrestores有所有权限。
$ example/rbac/create_role.sh
Creating role with ROLE_NAME=etcd-operator, NAMESPACE=default
clusterrole.rbac.authorization.k8s.io/etcd-operator created
Creating role binding with ROLE_NAME=etcd-operator, ROLE_BINDING_NAME=etcd-operator, NAMESPACE=default
clusterrolebinding.rbac.authorization.k8s.io/etcd-operator created
$ kubectl describe clusterrolebindings.rbac.authorization.k8s.io etcd-operator
Name: etcd-operator
Labels: <none>
Annotations: <none>
Role:
Kind: ClusterRole
Name: etcd-operator
Subjects:
Kind Name Namespace
---- ---- ---------
ServiceAccount default default
$ kubectl describe clusterrole etcd-operator
Name: etcd-operator
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
endpoints [] [] [*]
events [] [] [*]
persistentvolumeclaims [] [] [*]
pods [] [] [*]
services [] [] [*]
customresourcedefinitions.apiextensions.k8s.io [] [] [*]
deployments.apps [] [] [*]
etcdbackups.etcd.database.coreos.com [] [] [*]
etcdclusters.etcd.database.coreos.com [] [] [*]
etcdrestores.etcd.database.coreos.com [] [] [*]
secrets [] [] [get]
Deploy Etcd Operator
Etcd Operator 本身就是一个Deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: etcd-operator
spec:
replicas: 1
template:
metadata:
labels:
name: etcd-operator
spec:
containers:
- name: etcd-operator
image: quay.io/coreos/etcd-operator:v0.9.3
command:
- etcd-operator
# Uncomment to act for resources in all namespaces. More information in doc/user/clusterwide.md
#- -cluster-wide
env:
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
直接创建就可以:
$ kubectl apply -f example/deployment.yaml
deployment.extensions/etcd-operator created
Etcd Operator的Pod进入Running状态,CRD就会被自动创建出来:
- Name:
etcdclusters.etcd.database.coreos.com - API Group:
etcd.database.coreos.com - API Kind:
EtcdCluster
$ kubectl get crd
NAME CREATED AT
etcdclusters.etcd.database.coreos.com 2019-01-16T01:40:36Z
$ kubectl describe crd etcdclusters.etcd.database.coreos.com
Name: etcdclusters.etcd.database.coreos.com
Namespace:
Labels: <none>
Annotations: <none>
API Version: apiextensions.k8s.io/v1beta1
Kind: CustomResourceDefinition
Metadata:
Creation Timestamp: 2019-01-16T01:40:36Z
Generation: 1
Resource Version: 7260
Self Link: /apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions/etcdclusters.etcd.database.coreos.com
UID: b8d35097-192f-11e9-9c3a-080027c2b927
Spec:
Conversion:
Strategy: None
Group: etcd.database.coreos.com
Names:
Kind: EtcdCluster
List Kind: EtcdClusterList
Plural: etcdclusters
Short Names:
etcd
......
Etcd Operator本身就是个自定义资源类型对应的自定义控制器。
Deploy Etcd Cluster
部署Etcd集群,如下就是部署一个EtcdCluster的CR,Etcd节点数为3,yaml如下:
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.2.13"
部署etcd集群,通过修改yaml就可以scale,upgrade集群,Operator保证集群可以failover:
$ kubectl apply -f example/example-etcd-cluster.yaml
etcdcluster.etcd.database.coreos.com/example-etcd-cluster created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-lcxlcf6d8x 1/1 Running 0 55s
example-etcd-cluster-mg8x9h4xfg 1/1 Running 0 111s
example-etcd-cluster-z8ckrc7cvd 1/1 Running 0 95s
Access Etcd Cluster
Etcd Operator创建集群后,会自动创建一个client service,通过这个Cluster IP和Port就可以访问Etcd集群:
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
example-etcd-cluster ClusterIP None <none> 2379/TCP,2380/TCP 18m
example-etcd-cluster-client ClusterIP 10.106.102.1 <none> 2379/TCP 18m
在Pod里面就可以访问Etcd集群:
$ kubectl run --rm -i --tty fun --image quay.io/coreos/etcd:v3.2.13 --restart=Never -- /bin/sh
/ # ETCDCTL_API=3 etcdctl --endpoints http://example-etcd-cluster-client:2379 member list
74b19bcfe1048628, started, example-etcd-cluster-z8ckrc7cvd, http://example-etcd-cluster-z8ckrc7cvd.example-etcd-cluster.default.svc:2380, http://example-etcd-cluster-z8ckrc7cvd.example-etcd-cluster.default.svc:2379
82f4a1214aae8562, started, example-etcd-cluster-mg8x9h4xfg, http://example-etcd-cluster-mg8x9h4xfg.example-etcd-cluster.default.svc:2380, http://example-etcd-cluster-mg8x9h4xfg.example-etcd-cluster.default.svc:2379
a3ca3926e767f7e0, started, example-etcd-cluster-lcxlcf6d8x, http://example-etcd-cluster-lcxlcf6d8x.example-etcd-cluster.default.svc:2380, http://example-etcd-cluster-lcxlcf6d8x.example-etcd-cluster.default.svc:2379
/ # ETCDCTL_API=3 etcdctl --endpoints http://example-etcd-cluster-client:2379 put /test/ok 22
OK
/ # ETCDCTL_API=3 etcdctl --endpoints http://example-etcd-cluster-client:2379 get /test/ok
/test/ok
22
Other
还可以通过Helm部署Operator。
https://github.com/helm/charts/tree/master/stable/etcd-operator
How Etcd Operator Works
Operator 就是利用Kubernetes的CRD,来描述我们要部署的“有状态应用”,然后在自定义控制器里,通过自定义API对象的变化,完成具体的部署和运维工作。
编写一个Etcd Operator 跟编写一个自定义控制器没啥区别。
Etcd Operator部署Etcd集群,采用的是静态集群Static的方式,没有采用动态集群的方式。
静态集群部署前需要规划好集群拓扑结构,和各个节点的固定IP。
$ etcd --name infra0 --initial-advertise-peer-urls http://10.0.1.10:2380 \
--listen-peer-urls http://10.0.1.10:2380 \
...
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new
$ etcd --name infra1 --initial-advertise-peer-urls http://10.0.1.11:2380 \
--listen-peer-urls http://10.0.1.11:2380 \
...
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new
$ etcd --name infra2 --initial-advertise-peer-urls http://10.0.1.12:2380 \
--listen-peer-urls http://10.0.1.12:2380 \
...
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new
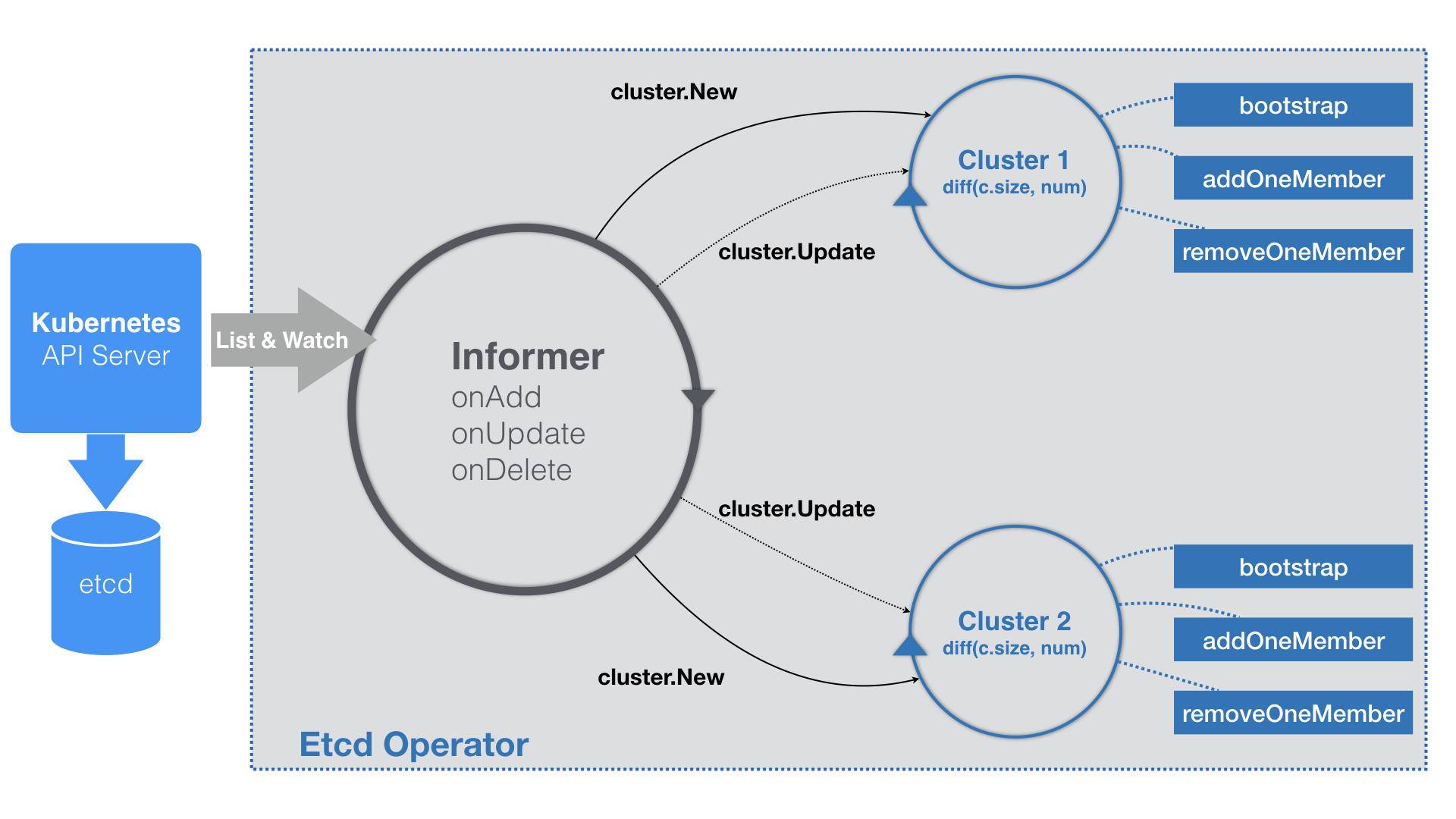
- 没有使用WorkQueue。
// TODO: use workqueue to avoid blocking
...
- 对每一个EtcdCluster对象,都启动了一个控制循环,“并发”的响应这些对象的变化。
- Bootstrap 创建一个“种子节点”。种子节点和普通节点区别是-initial-cluster-state这个参数的值,new代表种子节点,existing为普通节点,Etcd Operator需要把普通节点加入到集群。
- Add/RemoveOneMember 给集群创建或者移除Etcd节点,直到集群的节点数等于size。
- 当Pod还没创建出来,IP也没被分配,Cluster对象会事先创建一个于该EtcdCluster同名的Headless Service。这样Etcd Operator在接下来的所有创建Pod步骤里,就都可以使用Pod的DNS记录(...svc.cluster.local)来替代它的IP地址了。
- addOneMember:
- 生成一个新节点的Pod的名字,比如:example-etcd-cluster-xxx;
- 调用Etcd Client,etcdctl member add example-etcd-cluster-xxx命名。
- 使用这个Pod 名字,和已经存在的所有节点列表,组成inital-cluster字段,使用这个字段生成Pod里面的Etcd容器的启动命令:
/usr/local/bin/etcd --data-dir=/var/etcd/data --name=example-etcd-cluster-v6v6s6stxd --initial-advertise-peer-urls=http://example-etcd-cluster-v6v6s6stxd.example-etcd-cluster.default.svc:2380 --listen-peer-urls=http://0.0.0.0:2380 --listen-client-urls=http://0.0.0.0:2379 --advertise-client-urls=http://example-etcd-cluster-v6v6s6stxd.example-etcd-cluster.default.svc:2379 --initial-cluster=example-etcd-cluster-mbzlg6sd56=http://example-etcd-cluster-mbzlg6sd56.example-etcd-cluster.default.svc:2380,example-etcd-cluster-v6v6s6stxd=http://example-etcd-cluster-v6v6s6stxd.example-etcd-cluster.default.svc:2380 --initial-cluster-state=existing
- removeOneMember 类似;
- addOneMember/removeOneMember使用的是Pod的名字,而不是DNS,这些操作会更新Etcd内部维护的拓扑信息,不许集群外部 通过固定编号来固定这个拓扑关系(StatefullSet需要通过编号来固定)。
- Etcd基于Raft协议的Key-value存储,只要半数以下节点失效,当前集群依然正常可用,Etcd Operator通过控制循环创建新Pod加入集群,这个集群会一直可用,所以不需要对每个节点的data持久化。
- 如果半数以上节点失效,集群就丧失了写入能力,进入不可用状态,新创的Pod也无法自动恢复起来了,为了解决这个问题,又有一个Etcd Backup/Restore Operator负责完成对集群进行备份和恢复工作,这两个Operator也在etcd-operator项目中。
Operator SDK
CoreOS 为了方便用户开发Operator,推出了Operator SDK 即operator-framework,简化了开发步骤。