概述
容器其实就是一种沙盒技术的,沙盒就像集装箱一样,把应用装起来,应用于应用之间,有了边界,互不干扰,而且方便被搬来搬去,这就是PaaS最理想的状态。
程序在操作系统的表现就是进程,容器技术的核心功能就是通过约束和修改进程的动态表现,创造出一个“边界”。Linux操作系统中,Cgroups技术是用来制造约束的手段,Namespace技术是用来修改进程视图的主要方法。
隔离技术(Namespace)
举个例子:
运行busybox容器,执行/bin/sh,在跑个sleep。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ docker run -it busybox /bin/sh
/ #
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
7 root 0:00 ps
/ #
/ # sleep 100 &
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
9 root 0:00 sleep 100
10 root 0:00 ps
/ # |
宿主机上的进程
1 2 3 4 5 6 7 |
[root@yzw zhiweiyin]# ps auxf USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1122 0.3 1.7 729148 66444 ? Ssl 08:14 0:10 /usr/bin/dockerd root 1318 0.5 0.7 574660 30976 ? Ssl 08:14 0:16 \_ docker-containerd --config /var/run/docker/containerd/containerd.toml root 4511 0.0 0.0 7488 3156 ? Sl 08:58 0:00 \_ docker-containerd-shim -namespace moby -workdir /var/lib/docker/containerd/daemon/io.containerd.runtime.v1.linux/moby root 4529 0.0 0.0 1252 264 pts/0 Ss 08:58 0:00 \_ /bin/sh root 4671 0.0 0.0 1232 4 pts/0 S+ 09:01 0:00 \_ sleep 100 |
容器里面sh的进程号是1,但是在宿主机上进程号是4529,且是docker-containerd-shim的子进程,sleep也是类似,这就是Namespace机制,容器里面屏蔽掉了其他进程和进程号。
Linux上创建线程是用clone,返回一个PID号。
1
|
int pid = clone(main_function,stack_size,SIGCHID,NULL) |
当我们加上CLONE_NEWPID参数后,新创建的这个进程就会“看到”是一个全新的进程空间,在这个进程空间里PID是1。但是在主机上仍然是另外的PID号。多次执行clone会创建多个PID Namespace出来,每个进程里面PID都为1,看不到真正的宿主机上的PID,也看不到其他PID Namespace里的情况。
1
|
int pid = clone(main_function,stack_size,CLONE_NEWPID|SIGCHID,NULL) |
Mount Namespace 用于被隔离进程只看到当前Namespace里的挂载点信息。
Network Namespace 用于被隔离进程只看到当前Namespace里面的网络设备和配置。
这就是Linux容器实现的原理。创建容器进程时,指定了这个进程所需要启动的一组Namespace参数,这样容器就只能“看”到当前容器Namespace所限定的资源、文件、设置、状态、或者配置了,对于宿主机和其他不相干的进程都看不到了。容器其实是一种特殊的进程而已。
虚拟机 vs. 容器
先看两张图:
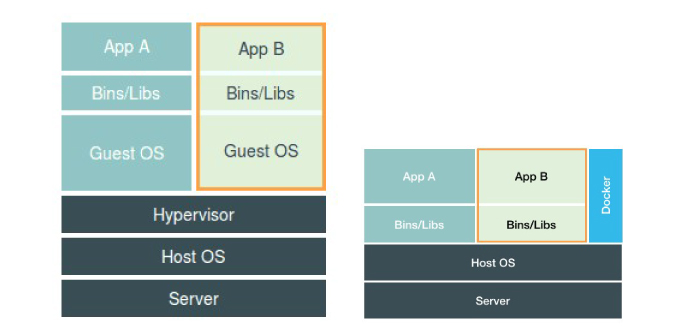
左边是虚拟机的工作原理,Hypervisor的软件通过硬件的虚拟化功能,模拟出了运行一个操作系统所以需要的各种硬件,然后在模拟的硬件上按照一个操作系统 Guest OS,软件进程跑在这个Guest OS里,也就只能看到这个OS里面的文件和目录,以及虚拟设备。所以虚拟机也能隔离作用,但是开销太大,太重了,一个最小的CentOS KVM虚机启动后差不多需要100-200M内存,所有对资源的使用都得经过序集合软件,又是一层损耗。
右边是容器的工作原理,Docker的位置是个应用一个级别的,和宿主机上其他应用进程是相同级别的,由宿主机统一管理,只不过被隔离的进程,额外设置了Namespace参数,Docker扮演的角色是辅助和管理,和Hypervisor完全不同。容器相对于虚机机来说几乎无损耗,也无需单独的Guest OS。但是容器也有弊端,所有容器之间隔离的不彻底,所有容器共用操作系统内核,内核有很多资源是不能被Namespace化的,比如时间。虚机机里面就可以随便这套了。所有应用容器化后什么可以做什么不可以做是需要考虑的一个问题,特别是对系统调用的使用上。
资源限制技术 Cgroups
通过Namespace技术虽然实现了容器的资源隔离,但是这个进程还是在宿主机上跑的,和其他进程共享CPU和内存的,有可能把宿主机上的CPU和内存吃完,Cgroups就是用来对进程设置资源限制的主要功能。
Linux Cgroups 全称 Linux Control Group,限制一个进程使用的资源上限,包括CPU,内存,磁盘,网络带宽等。还可以对进程进行优先级设置,审计,将进程挂起和恢复等操作。
Cgroups 给用户暴露出来的操作接口是文件系统,在/sys/fs/cgroup路径下,包括了各种限制资源类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
[root@yzw ~]# mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event) [root@yzw cgroup]# ll /sys/fs/cgroup/ total 0 drwxr-xr-x. 5 root root 0 Sep 10 22:48 blkio lrwxrwxrwx. 1 root root 11 Sep 10 22:48 cpu -> cpu,cpuacct lrwxrwxrwx. 1 root root 11 Sep 10 22:48 cpuacct -> cpu,cpuacct drwxr-xr-x. 5 root root 0 Sep 10 22:48 cpu,cpuacct drwxr-xr-x. 3 root root 0 Sep 10 22:48 cpuset drwxr-xr-x. 5 root root 0 Sep 10 22:48 devices drwxr-xr-x. 3 root root 0 Sep 10 22:48 freezer drwxr-xr-x. 3 root root 0 Sep 10 22:48 hugetlb drwxr-xr-x. 5 root root 0 Sep 10 22:48 memory lrwxrwxrwx. 1 root root 16 Sep 10 22:48 net_cls -> net_cls,net_prio drwxr-xr-x. 3 root root 0 Sep 10 22:48 net_cls,net_prio lrwxrwxrwx. 1 root root 16 Sep 10 22:48 net_prio -> net_cls,net_prio drwxr-xr-x. 3 root root 0 Sep 10 22:48 perf_event drwxr-xr-x. 5 root root 0 Sep 10 22:48 pids drwxr-xr-x. 5 root root 0 Sep 10 22:48 systemd |
举个例子:
cfs_period和cfs_quota组合使用,限制进程在cfs_period的一段时间内,只能被分到总量为cfs_quota的CPU时间。
在/sys/fs/cgroup/cpu目录下创建container文件夹,系统自动创建了一堆资源限制文件。这个目录就成为一个“控制组”。
1 2 3 4 |
[root@yzw cpu]# mkdir container [root@yzw cpu]# ls container/ cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks |
我们后台执行个死循环,top发现CPU1被吃完了,container控制组quota没有限制,period是100ms(100000us)。
我们修改配置,quota写入20ms就是说100ms该控制组的进程只能使用20ms的CPU,这个进程只使用20%的CPU带宽,我们把限制的进程PID写入该控制组。
再次top发现CPU1的使用率降下来了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[root@yzw cpu]# while :; do : ;done & [1] 3592 [root@yzw cpu]# top %Cpu1 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st [root@yzw container]# cat cpu.cfs_period_us 100000 [root@yzw container]# cat cpu.cfs_quota_us -1 [root@yzw container]# echo 20000 > cpu.cfs_quota_us [root@yzw container]# echo 3592 > tasks [root@yzw container]# top %Cpu1 : 17.4 us, 0.0 sy, 0.0 ni, 82.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st |
Cgroups的设计比较简单粗暴,就是一个子系统目录加上一组资源限制文件的组合。Docker等容器项目来说就是在各个子系统下,为每个容器创建一个控制组(就是新建个目录),然后启动容器进程后,把容器进程的PID写入对应控制组的tasks文件中就可以了。
1 2 3 4 5 6 7 8 9 |
[root@yzw docker]# docker run -it --cpu-period=100000 --cpu-quota=20000 centos:7 /bin/bash [root@90c9fd20daf8 /]# [root@yzw ~]# cd /sys/fs/cgroup/cpu/docker/90c9fd20daf8f4f9ad384d349d37ca1542490d78daf4e3fe6b79f3ad6d7179bd/ [root@yzw 90c9fd20daf8f4f9ad384d349d37ca1542490d78daf4e3fe6b79f3ad6d7179bd]# cat cpu.cfs_quota_us 20000 [root@yzw 90c9fd20daf8f4f9ad384d349d37ca1542490d78daf4e3fe6b79f3ad6d7179bd]# cat cpu.cfs_period_us 100000 [root@yzw 90c9fd20daf8f4f9ad384d349d37ca1542490d78daf4e3fe6b79f3ad6d7179bd]# |
总结
容器就是一个启动了多个Namespace的应用进程,这个进程能够使用的资源量,通过Cgroups配置限制。 容器技术中一个非常重要的概念,容器是一个单进程模型。 用户的应用进程就是容器里面PID=1的进程,其他后续创建的进程都是这个进程的子进程,意味着你没法运行两个不同的应用,除非找到一个公共的PID=1的程序来充当两个不同程序的父进程。好多人使用systemd或者superviord来充当容器的启动进程。 容器的设计希望容器和进程应用同生命周期,对后续编排很重要,如果容器是正常运行的,里面的应用挂了,处理起来就很麻烦。
issue
跟Namespace一样,Cgroups也有缺陷,提起最多的就是/proc文件系统的问题。/proc存储的是内核运行状态的一系列特殊文件,用户可以访问这些文件查看当前运行的进程的状态,比如CPU使用情况,内存使用情况,这些是top的主要数据来源。但是/proc不了解Cgroups的存在,就是容器里面读取的CPU核数,内存状态其实是宿主机的,会带来很多困惑和风险。
lxcfs可以增强docker资源的可见性,可解决这个问题。做法是把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到Docker容器的/proc/meminfo位置后。容器中进程读取相应文件内容时,LXCFS的FUSE实现会从容器对应的Cgroup中读取正确的内存限制。从而使得应用获得正确的资源约束设定。kubernetes环境下,也能用,以ds 方式运行 lxcfs ,自动给容器注入争取的 proc 信息。
/proc文件系统的问题我好像遇到过这个坑..当时在容器上运行的java应用,由于当时jvm参数没正确配置上,就用默认的,而容器设置的内存为4g,最后oom了,当时用命令查看容器的内存占用情况,竟然发现内存竟然有60多g。 那应该显示的是宿主机的内存了,jvm按照宿主机内存大小分配的默认内存应该大于4g 所以还没full gc 就oom了